

の続き.PINE A64+ がどの程度の性能なのかを調べてみた備忘録です.まずは,UnixBench の結果から.
UnixBench on PINE A64+
性能評価と言えば,ベンチマークだろってことで,Unix 系のベンチマークソフトを調べてみると,UnixBench というのが有名らしい.
GitHub で配布されているので,早速取ってきて実行してみます.
$ git clone https://github.com/kdlucas/byte-unixbench $ cd byte-unixbench/UnixBench/ $ ./Run
でスタートです.1時間くらい掛かりました.結果は(適当に抜粋しています),
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: pine64: GNU/Linux
OS: GNU/Linux -- 3.10.105-0-pine64-longsleep -- #3 SMP PREEMPT Sat Mar 11 16:05:53 CET 2017
Machine: aarch64 (aarch64)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
23:28:18 up 18 min, 1 user, load average: 0.33, 0.17, 0.08; runlevel 2018-01-02
------------------------------------------------------------------------
Benchmark Run: 火 1月 02 2018 23:28:18 - 23:56:27
4 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 6094928.5 lps (10.0 s, 7 samples)
Double-Precision Whetstone 1065.9 MWIPS (10.0 s, 7 samples)
Execl Throughput 565.2 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 134212.9 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 41079.4 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 325478.5 KBps (30.0 s, 2 samples)
Pipe Throughput 337516.3 lps (10.0 s, 7 samples)
Pipe-based Context Switching 61156.5 lps (10.0 s, 7 samples)
Process Creation 1737.3 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 2249.6 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 726.2 lpm (60.1 s, 2 samples)
System Call Overhead 749398.9 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 6094928.5 522.3
Double-Precision Whetstone 55.0 1065.9 193.8
Execl Throughput 43.0 565.2 131.4
File Copy 1024 bufsize 2000 maxblocks 3960.0 134212.9 338.9
File Copy 256 bufsize 500 maxblocks 1655.0 41079.4 248.2
File Copy 4096 bufsize 8000 maxblocks 5800.0 325478.5 561.2
Pipe Throughput 12440.0 337516.3 271.3
Pipe-based Context Switching 4000.0 61156.5 152.9
Process Creation 126.0 1737.3 137.9
Shell Scripts (1 concurrent) 42.4 2249.6 530.6
Shell Scripts (8 concurrent) 6.0 726.2 1210.4
System Call Overhead 15000.0 749398.9 499.6
========
System Benchmarks Index Score 320.0
------------------------------------------------------------------------
Benchmark Run: 火 1月 02 2018 23:56:27 - 00:24:39
4 CPUs in system; running 4 parallel copies of tests
Dhrystone 2 using register variables 24372034.2 lps (10.0 s, 7 samples)
Double-Precision Whetstone 4258.1 MWIPS (10.0 s, 7 samples)
Execl Throughput 3058.1 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 223907.3 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 55924.5 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 636029.5 KBps (30.0 s, 2 samples)
Pipe Throughput 1349862.0 lps (10.0 s, 7 samples)
Pipe-based Context Switching 239937.8 lps (10.0 s, 7 samples)
Process Creation 9287.1 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 5858.9 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 774.3 lpm (60.2 s, 2 samples)
System Call Overhead 2821562.5 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 24372034.2 2088.4
Double-Precision Whetstone 55.0 4258.1 774.2
Execl Throughput 43.0 3058.1 711.2
File Copy 1024 bufsize 2000 maxblocks 3960.0 223907.3 565.4
File Copy 256 bufsize 500 maxblocks 1655.0 55924.5 337.9
File Copy 4096 bufsize 8000 maxblocks 5800.0 636029.5 1096.6
Pipe Throughput 12440.0 1349862.0 1085.1
Pipe-based Context Switching 4000.0 239937.8 599.8
Process Creation 126.0 9287.1 737.1
Shell Scripts (1 concurrent) 42.4 5858.9 1381.8
Shell Scripts (8 concurrent) 6.0 774.3 1290.6
System Call Overhead 15000.0 2821562.5 1881.0
========
System Benchmarks Index Score 924.1
見方ですが,Unixbench は SPARCstation 20-61 の性能を10としているらしく,値が大きいほど高性能らしい.懐かしいですねぇ.SPARCStation 20 ですか.大学に何台かおいてありましたが,200万円するんだよって聞き「へ〜」と思った記憶があります.しかし ,今更SPARCStation 20 と比較してもよくわからないので,手持ちの MacBook Air 11inch Mid 2013 で測定してみた結果と,UnixBench の結果が載せられているいくつかのWebページのリンクを示しておきます.
$ wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/byte-unixbench/UnixBench5.1.3.tgz
$ tar -zxvf UnixBench5.1.3.tgz
$ git clone https://gist.github.com/barusan/11033924
$ cd UnixBench
$ patch -p1 < ../11033924/UnixBench5.1.3.mavericks.patch
.....
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: macbookair.local: Darwin
OS: Darwin -- 17.3.0 -- Darwin Kernel Version 17.3.0: Thu Nov 9 18:09:22 PST 2017; root:xnu-4570.31.3~1/RELEASE_X86_64
Machine: x86_64 (unknown)
Language: en_US.utf8 (charmap="US-ASCII", collate=)
CPU 0: Intel(R) Core(TM) i5-4250U CPU @ 1.30GHz (0.0 bogomips)
MMX, Physical Address Ext, SYSENTER/SYSEXIT, Intel virtualization
CPU 1: Intel(R) Core(TM) i5-4250U CPU @ 1.30GHz (0.0 bogomips)
MMX, Physical Address Ext, SYSENTER/SYSEXIT, Intel virtualization
CPU 2: Intel(R) Core(TM) i5-4250U CPU @ 1.30GHz (0.0 bogomips)
MMX, Physical Address Ext, SYSENTER/SYSEXIT, Intel virtualization
CPU 3: Intel(R) Core(TM) i5-4250U CPU @ 1.30GHz (0.0 bogomips)
MMX, Physical Address Ext, SYSENTER/SYSEXIT, Intel virtualization
11:57 up 4 days, 19:28, 2 users, load averages: 1.73 2.05 2.76; runlevel 3
------------------------------------------------------------------------
Benchmark Run: 金 1 05 2018 11:57:07 - 12:25:46
4 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 25815584.8 lps (10.0 s, 7 samples)
Double-Precision Whetstone 4042.7 MWIPS (9.9 s, 7 samples)
Execl Throughput 288.8 lps (29.4 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 192763.0 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 49158.3 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 670702.0 KBps (30.0 s, 2 samples)
Pipe Throughput 397083.5 lps (10.0 s, 7 samples)
Pipe-based Context Switching 66524.0 lps (10.0 s, 7 samples)
Process Creation 1286.3 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 2069.6 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 449.9 lpm (60.1 s, 2 samples)
System Call Overhead 283373.1 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 25815584.8 2212.1
Double-Precision Whetstone 55.0 4042.7 735.0
Execl Throughput 43.0 288.8 67.2
File Copy 1024 bufsize 2000 maxblocks 3960.0 192763.0 486.8
File Copy 256 bufsize 500 maxblocks 1655.0 49158.3 297.0
File Copy 4096 bufsize 8000 maxblocks 5800.0 670702.0 1156.4
Pipe Throughput 12440.0 397083.5 319.2
Pipe-based Context Switching 4000.0 66524.0 166.3
Process Creation 126.0 1286.3 102.1
Shell Scripts (1 concurrent) 42.4 2069.6 488.1
Shell Scripts (8 concurrent) 6.0 449.9 749.8
System Call Overhead 15000.0 283373.1 188.9
========
System Benchmarks Index Score 371.2
------------------------------------------------------------------------
Benchmark Run: 金 1 05 2018 12:25:46 - 12:54:43
4 CPUs in system; running 4 parallel copies of tests
Dhrystone 2 using register variables 54322521.4 lps (10.0 s, 7 samples)
Double-Precision Whetstone 14804.5 MWIPS (10.0 s, 7 samples)
Execl Throughput 703.7 lps (29.5 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 257623.0 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 74024.7 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1034918.1 KBps (30.0 s, 2 samples)
Pipe Throughput 920645.6 lps (10.0 s, 7 samples)
Pipe-based Context Switching 230121.9 lps (10.0 s, 7 samples)
Process Creation 3152.7 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 3930.7 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 555.5 lpm (60.2 s, 2 samples)
System Call Overhead 700282.6 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 54322521.4 4654.9
Double-Precision Whetstone 55.0 14804.5 2691.7
Execl Throughput 43.0 703.7 163.6
File Copy 1024 bufsize 2000 maxblocks 3960.0 257623.0 650.6
File Copy 256 bufsize 500 maxblocks 1655.0 74024.7 447.3
File Copy 4096 bufsize 8000 maxblocks 5800.0 1034918.1 1784.3
Pipe Throughput 12440.0 920645.6 740.1
Pipe-based Context Switching 4000.0 230121.9 575.3
Process Creation 126.0 3152.7 250.2
Shell Scripts (1 concurrent) 42.4 3930.7 927.1
Shell Scripts (8 concurrent) 6.0 555.5 925.9
System Call Overhead 15000.0 700282.6 466.9
========
System Benchmarks Index Score 772.9

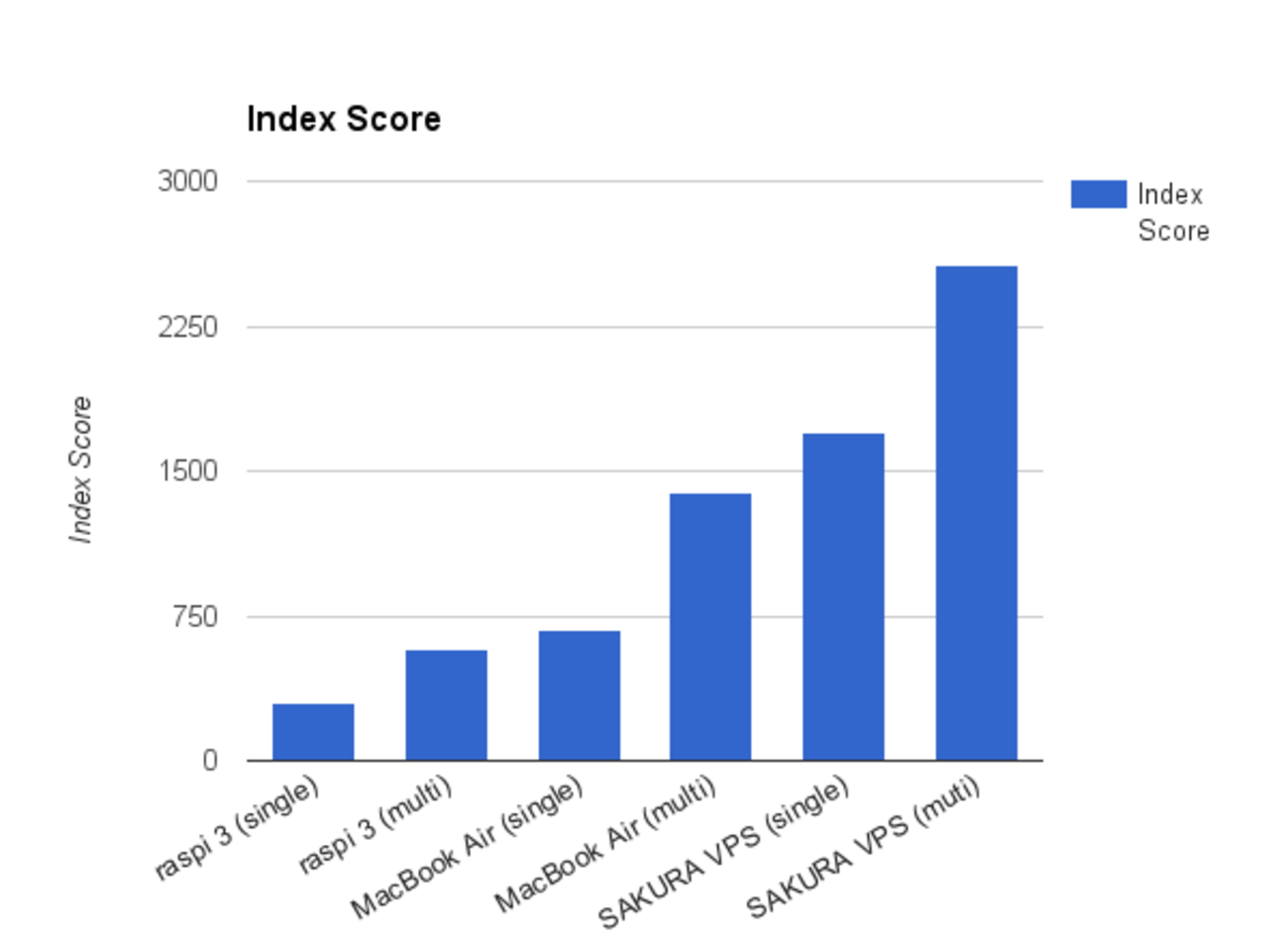
う〜ん.大体ちょっと前の Atom 以上初代 core i3 以下って感じなんですね.なぜか MacBook Air 11 mid 2013 の値が低いですが,クロック数が 1.3GHz と低いからでしょうか.そして,Raspberry pi3 よりも確かに少しだけ速いみたい.さすがに最近の core i5 とかには全く敵いませんが,消費電力のことを考慮すると驚くほど高性能です.
なお,CPU温度やクロック数は
$ sudo pine64_health.sh CPU freq : 1152.00 MHz CPU count : 4 Governor : interactive Core voltage : 1.30 V SOC Temp : 44 C Cooling state : 0 Cooling limit : roomage:0,0,0,0,1152000,4,0,0
で確認できますが,ベンチマーク中,4コア使うところに差し掛かると CPU の温度が75度とかすぐにいくので,ヒートシンクは付けた方が良さそうです,
AES-NI 対応について
PINE A64+ は AES による暗号と複合をハードウェア支援する AES-NI に対応しているらしく,実際,
$ cat /proc/cpuinfo Processor : AArch64 Processor rev 4 (aarch64) processor : 0 processor : 1 processor : 2 processor : 3 Features : fp asimd aes pmull sha1 sha2 crc32 CPU implementer : 0x41 CPU architecture: AArch64 CPU variant : 0x0 CPU part : 0xd03 CPU revision : 4 Hardware : sun50iw1p1
としてみると,確かに Features の欄に aes の記述があります.もちろん,ソフトが対応してないと意味はないのですが,openssl は(少なくともソースコード的には)対応のようで,
-
openssl speed aes-256-cbc: AES-NI なし/1コア
-
openssl speed -evp aes-256-cbc: AES-NI あり/1コア
- openssl speed -evp aes-256-cbc -multi 4: AES-NIあり/4コア
のように実行すれば良さそう.実際に実行してみると,
$ openssl speed aes-256-cbc ..... The 'numbers' are in 1000s of bytes per second processed. type 16 bytes 64 bytes 256 bytes 1024 bytes 8192 bytes aes-256 cbc 30228.77k 31523.73k 32185.71k 32345.56k 32426.44k $ $ openssl speed -evp aes-256-cbc ..... The 'numbers' are in 1000s of bytes per second processed. type 16 bytes 64 bytes 256 bytes 1024 bytes 8192 bytes aes-256-cbc 131464.72k 305291.91k 449934.49k 520959.13k 545998.19k $ $ openssl speed -evp aes-256-cbc -multi 4 ..... The 'numbers' are in 1000s of bytes per second processed. type 16 bytes 64 bytes 256 bytes 1024 bytes 8192 bytes aes-256-cbc 516652.79k 1201234.75k 1765172.05k 2048354.65k 2142636.71k
のようになります.1コアで1秒間にどれだけ処理できたかを表す値のようなので,数字が大だと高性能だということで,見ての通り,どの場合もだいたい10倍以上違います.AES-NI なしの i5-2520M CPU @ 2.50GHz(Thinkpad X220) でやってみた結果は以下の通り.
$ openssl speed aes-256-cbc The 'numbers' are in 1000s of bytes per second processed. type 16 bytes 64 bytes 256 bytes 1024 bytes 8192 bytes aes-256 cbc 66418.15k 71288.29k 70846.59k 174448.16k 174760.84k
さすがに AES-NI 支援なしだと i5-2520 の方が2倍以上高速ですが,支援有りだと PINE A64+ の方が逆に2倍以上速いです.AES-NI 支援有りCPUでどれだけ性能が変わるのかは,

あたりを参照してください(うーん Ryzen ってとっても速いのね).
ところで,openssl の AES-NI サポートって,いろいろなサイトで,openssl engine -t -c とやって,aes というオプションが読み込まれているかどうかを調べるとありますが,PINE A64+ で実際にやってみると,
$ openssl engine -t -c
(dynamic) Dynamic engine loading support
[ unavailable ]
となり,AES-NI のサポートがない様にみえます.しかし,

なんかを見ると,最近の openssl だとデフォルト AES-NI は有効になるとあり,実際,ベンチマークの結果をみてもきちんとアクセラレーションできていますので,これは少し古い情報だと考えるべきでしょう.
PINE A64+ を何に使うか?
ここまで,PINE A64+ の性能を評価してきましたが,Gigabit Ethernet に対応していて,さらにCPUの性能は決して低くなく,さらに AES-NI に対応しているとなれば,
VPN Server にするのが良い!
んじゃないかなと思いましたので,この方向で本機を設定しました.本件については,以下をご覧ください.
以上!